Introduction to postgresql cdc to kafka
In today’s data-driven world, the ability to stream and process real-time information is a game-changer. PostgreSQL cdc to kafka, a powerful open-source database, offers an efficient way to manage structured data. When combined with Kafka, a popular distributed event streaming platform, you unlock even greater potential for your applications.
Imagine having the capability to capture changes in your PostgreSQL database and instantly send those updates to Kafka topics. This seamless integration opens up new avenues for analytics, monitoring, and application development. If you’re seeking ways to enhance your data strategy or improve system responsiveness, understanding how to implement PostgreSQL CDC (Change Data Capture) into Kafka can be transformative.
Let’s delve into what makes this combination so compelling and guide you step by step through setting it up effectively.
ALSO READ: The Power of 99219444 Toshiba in Professional Displays
The Benefits of Using postgresql cdc to kafka
Utilizing PostgreSQL CDC to Kafka offers numerous advantages for businesses looking to manage data efficiently. One of the primary benefits is real-time data streaming. This capability allows organizations to process changes as they occur, enhancing responsiveness and decision-making.
Another significant advantage is scalability. As data volumes grow, Kafka’s distributed architecture ensures that applications can handle increased loads without compromising performance. This makes it ideal for high-demand environments.
Data consistency also improves with this setup. Changes captured from PostgreSQL are reliably sent to Kafka, ensuring that all systems reflect the same information seamlessly.
Moreover, integrating these technologies fosters a more robust analytics framework. Businesses can harness valuable insights from their live data streams, driving better strategies and operational efficiencies.
Using open-source solutions like PostgreSQL and Kafka reduces costs associated with proprietary software while providing flexibility in customization and deployment options.
Step-by-Step Guide to Setting up PostgreSQL CDC to Kafka
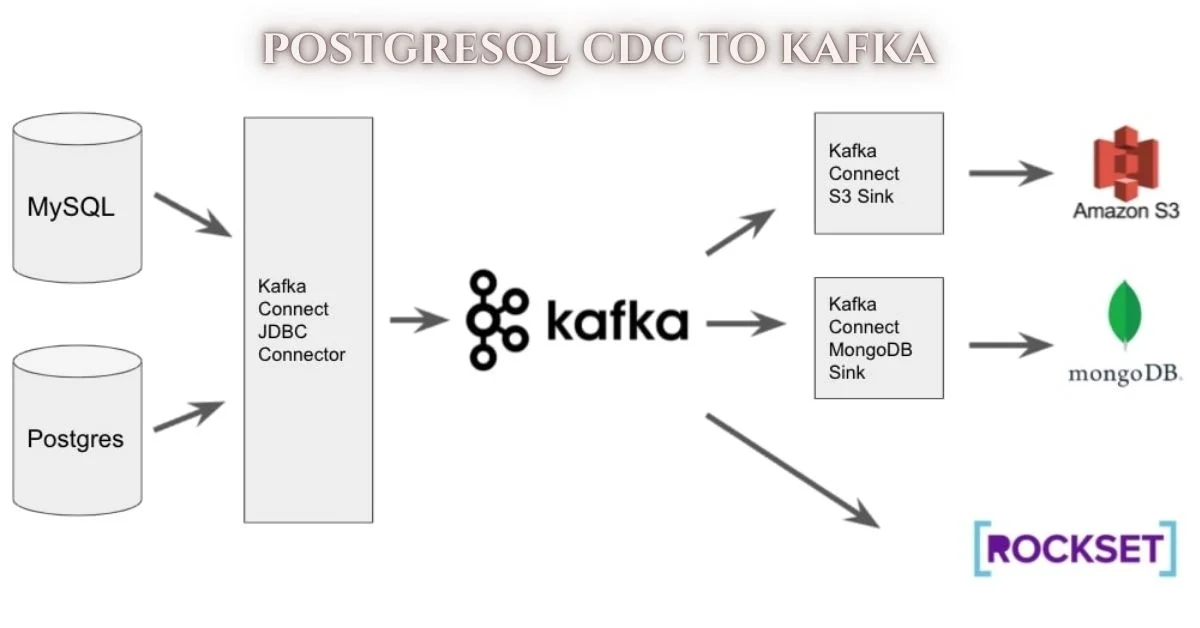
Setting up PostgreSQL CDC to Kafka involves several steps that ensure seamless data streaming. Begin by installing Debezium, an open-source CDC tool designed for this purpose.
Create a Kafka cluster if you haven’t already. This setup will act as your messaging system where the streamed changes from PostgreSQL will be published.
Next, configure PostgreSQL to enable logical replication. Modify the `postgresql.conf` file to set `wal_level` to ‘logical’ and add appropriate settings for maximum replication slots and connections.
Afterward, define a connector in Debezium that specifies which database tables you want to monitor. This is done through a JSON configuration file detailing connection information and topics.
Start the Kafka Connect process with the Debezium connector configured. You should now see real-time data flow from PostgreSQL directly into your specified Kafka topic without any hassle.
Common Challenges and Solutions
When implementing PostgreSQL CDC to Kafka, users often face the challenge of data consistency. This can arise from latency issues during replication processes. To mitigate this, ensure that your configuration is optimized for low-latency operations.
Another common hurdle is managing schema changes in PostgreSQL. These changes can lead to compatibility issues with Kafka consumer applications. A robust approach involves using a schema registry that accommodates versioning, allowing seamless updates without breaking existing integrations.
Monitoring and troubleshooting are also critical challenges. It’s essential to establish effective monitoring tools that alert you to failures or performance bottlenecks within the pipeline. Setting up dashboards for visual oversight helps maintain efficiency and quick response times.
Handling high-volume transactions might strain resources if not managed properly. Implementing partitioning strategies in Kafka can help distribute load while ensuring that PostgreSQL continues functioning smoothly under pressure.
Best Practices for Using PostgreSQL CDC with Kafka
To maximize the efficiency of PostgreSQL CDC to Kafka, start with careful schema design. Ensure that your database structures are normalized and optimized for change data capture. This minimizes unnecessary writes and enhances performance.
Next, utilize partitioning in Kafka topics based on relevant criteria like date or region. This practice can help improve read speeds and simplify consumer logic.
Monitor latency closely between your PostgreSQL changes and their appearance in Kafka. Set alerts to catch any lags promptly so you can take corrective action before they impact downstream applications.
Another key aspect is ensuring idempotency in consumers. This prevents duplication during message processing, which is crucial for maintaining data integrity across systems.
Regularly review your configuration settings for both PostgreSQL and Kafka as usage patterns evolve over time. Adjustments may be necessary to keep everything running smoothly.
Real-Life Examples of Companies Utilizing PostgreSQL CDC and Kafka
Many companies today are harnessing the power of PostgreSQL CDC to Kafka for enhanced data streaming and processing. For instance, a leading e-commerce platform leverages this integration to track user activities in real time. By capturing changes from their PostgreSQL databases, they send updates directly into Kafka topics, enabling instant analytics that drive personalized marketing campaigns.
A financial services firm also benefits from this architecture. They use PostgreSQL CDC to monitor transactions and feed data securely into Kafka. This allows them to detect anomalies quickly and respond effectively, significantly reducing fraud risk.
Moreover, a healthcare provider employs this setup for patient record management. As changes occur in their database, those updates stream through Kafka, ensuring that all relevant systems receive timely notifications about critical changes while maintaining compliance with regulations on sensitive information handling.
Conclusion
PostgreSQL CDC to Kafka presents a powerful solution for organizations looking to streamline their data workflows. By leveraging Change Data Capture, businesses can efficiently monitor and replicate changes in PostgreSQL databases while utilizing Kafka’s robust messaging capabilities.
Many companies have successfully implemented this architecture, resulting in improved real-time analytics and more responsive applications. As industries continue to evolve and data becomes increasingly critical, embracing PostgreSQL CDC with Kafka will ensure that your organization stays ahead of the curve.
As you explore these technologies, keep best practices in mind. Understand the challenges you may face and don’t hesitate to seek solutions tailored to your needs. The integration journey might be complex at times, but the rewards are well worth it for those willing to invest time and resources into mastering this synergy between PostgreSQL and Kafka.
ALSO READ: Expert Insights from Board Utility Consultant Mottershead
FAQs
What is “PostgreSQL CDC to Kafka”?
PostgreSQL CDC to Kafka refers to using Change Data Capture (CDC) to capture real-time changes in a PostgreSQL database and stream those updates to Kafka topics. This allows businesses to process and analyze data in real time, improving responsiveness and operational efficiency.
How does PostgreSQL CDC enhance real-time data streaming?
PostgreSQL CDC captures changes in real-time, allowing data updates from the database to be immediately sent to Kafka. This reduces latency and enables timely decision-making and faster response to customer needs.
What are the benefits of using PostgreSQL CDC with Kafka?
The combination offers real-time data streaming, scalability, improved data consistency, and enhanced analytics capabilities. It ensures that all systems stay synchronized and supports high-volume data processing.
What are common challenges when implementing PostgreSQL CDC to Kafka’s?
Some common challenges include managing data consistency, handling schema changes, monitoring the system, and addressing high-volume transactions. Solutions like optimizing configurations and using schema registries can mitigate these issues.
Can you provide real-life examples of PostgreSQL CDC and Kafka integration?
E-commerce platforms, financial services firms, and healthcare providers use this integration to track user activities, monitor transactions, and manage patient records in real-time, improving analytics and response times.